

We are surrounded by data. Data is collected on us everywhere we go, every transaction we make online or in person, every website we visit, every show we stream, and of course, in every survey we answer. Raw data, however, is difficult to comprehend, especially if there is a lot of it. We need a way to summarise the raw data, to capture the essence of the story it can tell us. This is where descriptive statistics comes to our help. Through descriptive statistics we can tell the story of where the middle of the data is (central tendency), how spread out the data is (dispersion), and, usually through visual representations, describe the shape of the data (skew and kurtosis).
Scientific research and most other research for that matter will result in the generation of a data set. This data set will contain all the measurements from a sample that has been gathered. These scores can be combined to form a distribution of scores. Once a distribution of scores is at hand it is desirable to summarise all their values using a very small number of numerical descriptors. For example, most people are familiar with the average, which is one descriptor of a data set and is achieved by adding all the values together and dividing by the number of measurements. Basically, there are two different but very popular and useful broad classes of arithmetic ways of summarising data for one variable only. They are often referred to as measures of central tendency and measures of dispersion, although there are quite a few synonyms (see below).
| Summary Statistic | Synonyms |
|---|---|
| Central Tendency | Measure of location Average Measures of typicality Measures of centre |
| Measures of Dispersion | Measures of spread Measures of variability Measures of Variation |
Measures of Central Tendency
We will start with a detailed discussion of the three "M’s" of central tendency — Mean, Median and Mode.
The (Arithmetic) Mean
The mean score is only appropriate for measurements made on interval or ratio level scales. The mean is simply the arithmetic average of all the scores in a distribution. As mentioned above, it is thus calculated by adding all the measurements together and then dividing by the total number of measurements. The sample mean is denoted 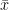

To illustrate how this formula works, consider the following example. Suppose you were to record the time (in minutes) it took you to walk from your house to your favourite cafe on nine separate occasions and your results were, in order:

The mean of these results is found by adding every time (including repetitions) and dividing by the number of times (including repetitions), and thus:

So we would conclude it takes you an average of 22.33 minutes (to 2 decimal places) or 22 minutes and 20 seconds, on average, to walk to your favourite cafe from your house.
It is imperative to only work out the mean when the nature of the data allows it. Suppose on one of those 9 mornings you had stopped to pet your neighbour’s cat and instead of 28 minutes, it actually took you 127 minutes to arrive at the cafe. Now your results would be:

There is only one change to the figures – the highest figure now reads 127 minutes instead of the original 28 minutes. This single change makes a large difference to the mean. It is now 33.33 minutes (33 minutes and 20 seconds), 11 minutes (or around 50%) higher than the first mean of 22.33 minutes. The effect of a single score on the mean can be profound. In other words a few scores with extreme values can have a large impact on the mean value. This can be a drawback in using the mean for descriptive purposes. You would be correct to argue that the mean can give a distorted view of the "centrality" of a data set where there are a few exceptional scores or outliers, or where the data are skewed significantly in one direction. In the context of recording travel times the figure of 127 minutes seems quite exceptional, and such a figure would need to be verified as representative and accurate (as should all data anyway). As a second example illustrating how unrepresentative a mean can be consider the following: A consultant has been employed to recommend the type of computer network a supplier might install in 25 offices in a certain region. The average sized office is quoted as having 160 workers. However, in the area considered there are in fact twenty 100-worker offices, four 300-worker offices and one 800-worker office. There is not one office close to 160 workers, the "average" size office. If the office size (as indicated by the number of workers) is related to the cost of each network then it would be most unwise for any individual office to base its network specifications on the average office size.
The "Flaw of Averages"
The media often makes statements about the "average" worker or "average" family, but one doesn’t really exist! A common misconception about averages is that they represent a "real" observation, for example, the average Australian family in the 1980s had 2.3 children. Anyone who has ever had to sit in the middle back seat of a family car from the 1980s would appreciate that the designers appear to have made the mistake of assuming that if they put 2.3 seats in the back, most families will be comfortable. The following cartoon from Jeff Danziger gives a good representation of someone making the same mistake as this:

The Median
As discussed in the previous section. There are many instances where the mean is unsuitable for describing the centrality of the data. The median may help in such situations.
The median (
For example, consider the eleven scores

They need to be re-ordered, as follows:

With an odd number of scores it is easy to identify the median. Here, the median score is 7 because it is the middle and sixth score. There are five scores below it and five above. Therefore, 
If the number of scores is even, the median is simply calculated by taking a value halfway between the middle pair. So for the ten scores below (already ranked in ascending order):

The median is by definition the value which splits the 5th and 6th value. Therefore,

In general we can see that the location of the median (of sorted data) is given by:

It should (hopefully) be obvious to you that if 
Now let’s revisit the example of the time taken to walk to the cafe from your house. Recall the two sets of data:}


What is the best measure of central tendency for the two data sets? For Set 1 the mean is 22.33 and for Set 2 it is 33.33. Why such a dramatic difference in the means? After all, the two sets only differ in one measurement. As indicated earlier the mean uses every score for its calculation, and so very large or very small scores will usually have a substantial bearing on the value of the mean, particularly for small data sets. Here it could well be argued that the median is the better measure. The median score is the fifth one in both sets, and its value is 22 in each. Why is the median frequently a preferred measure of central tendency? Here it is more typical of the time taken to walk to the cafe not only because it is literally the middle score but because it is uninfluenced by the 'rogue' outlier equalling 127.
The Mode
The mode is the most frequently occurring score in a distribution.
In other words, it is the score with the highest frequency. The mode is most useful for nominal variables where the median and mean cannot be calculated and would be absurd.
Consider the following data which refers to hair colour of a sample of 10 people (a nominal variable) where 1 = brown hair, 2 = blonde hair, 3 = grey hair and 4 = black hair:

The most frequently occurring category is 1 = brown hair. Therefore, brown hair is the modal category in this sample. Note that although we could compute the mean (1.9) or median (1.5) for these 10 numbers, there is no way we could interpret them sensibly. Does it make sense to say that the "average hair colour" is 1.9, or that half the people had "hair colour above 1.5"? Obviously neither the mean or median value would make sense here because it doesn’t make sense to do math with hair colour, e.g. brown hair plus blonde hair does not equal grey hair! If you are ever unsure whether or not to calculate the mean or median, first ask yourself if it makes sense to do math with what the numbers represent. It never makes sense to use the mean or median on nominal data.
The mode can also be calculated for ordinal, interval and ratio data. However, the median and mode are almost always better measures of central tendency in these situations. The mean, median, and mode are also important when looking at distributions, as are measures of dispersion.
Measures of Dispersion
A number of different measures of dispersion will be discovered in published research, statistics textbooks, or other sources. These measures are commonly referred to as "measures of spread" or "measures of variability". Depending upon whether the variables are nominal, ordinal, interval or ratio ones, some dispersion measures will be appropriate, some inappropriate and others plainly wrong. For example, there is no appropriate measure of spread at all for a variable measured at the nominal level; believe it or not! Upon finishing this segment on measures of dispersion, try using your understanding of what a nominal level variable is to work out why this is so. Four measures of spread are now considered. These are the range, the interquartile range, the variance and the standard deviation.
The Range
Conceptually, the range is by far the easiest measure of dispersion to understand. It is merely a matter of discerning the difference between the two most extreme values in a distribution of scores.

That is, the lowest and highest values are ascertained and then sometimes the two are quoted, or, more often, the smallest is subtracted from the largest to indicate the intervening "span" of scores.
So, turning again to the earlier example about the time taken to walk to the cafe from above, recall that the ordered data set was as follows:
The range is from 19 to 28 minutes. Strictly, the range is a difference and is calculated as (28 – 19) minutes = 9 minutes and is therefore presented as a single figure. In other words, the walk with the longest time was 9 minutes longer than the trip with the quickest time. Accordingly, the range of time, 9 minutes, represents the difference between the highest and lowest values. Notice that the range does not build into its calculation any but the two most extreme scores. This may be viewed as a legitimate criticism of the range as a useful or reliable measure of dispersion. Indeed, we can see this shortfall when we consider the alternate data set with the time that included petting the cat (i.e. 127 minutes). In that alternative data set, the range is now (127 – 19) minutes = 108 minutes. With one data point changed, the range has greatly increased!
The Interquartile Range
Before the interquartile range (IQR) is described, the concept of percentiles and quartiles must be discussed. Percentiles and quartiles are not measures of dispersion by themselves. They are needed to obtain the IQR.
Percentiles:
The notation 

Likewise, for example, 
Consider the following ordered data measuring the ages of a sample of 20 people (Note that to calculate percentiles or quartiles, the data must first be ordered):

Now lets determine the 25th percentile or 

where 


Solving for the 25th percentile results in the following:

which finds that the 25th percentile refers to the 5.5th ranked measurement (the rank halfway between 5 and 6) in the ordered data. Looking back to the data, we find that the 25th percentile lies between 19 (the 5th ranked value) and 21 (the 6th ranked value). Taking the average of these two values (use the mean formula given above), we find that 
Now what if we want 

Therefore, the 10.5th rank (mean value of 31 and 35 = 33) is

You have just discovered that the median is the 50th percentile.
Quartiles:
Quartiles break up a distribution into four parts and hence the name "quart"tile. Quartiles are denoted 




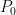
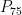

Using the 20 data points in age data above, let’s obtain the quartiles, 




Looking back at the data set of ages above, we find that

Whoops, we only have 20 people in the sample. So we just take the 20th rank which is a maximum value or highest observed age of 87. We now have all the pieces.
|
16 (Minimum) |
|
20 |
|
33 (Median) |
|
41 |
|
87 (Maximum) |
These 5 values comprise the 5-Number Summary (see definition below). We can now use these quartiles to obtain the IQR.
The 5-Number Summary
The 5-Number Summary is a summary of a data set of scores which includes the minimum value (

The Interquartile Range (IQR)
The difference between the third quartile,
The IQR is otherwise referred to as the quartile spread. The formula for the interquartile range is as follows:

Thus, the IQR embraces or spans the middle 50% of all the data. As well as being informative for this reason in describing one group of measurements, it is also useful for comparing two groups on the same variable.
Following on from our example above, let’s get the IQR for the age data. Recall that 


Outliers
An outlier is an unusually high or low value that does not look usual given the other data in a data set. The IQR is one value that can be used to help define outliers.
An outlier can be defined as any value that lies in the following regions:

This means that if an observation, 
Extreme (or probable) outliers and the Outer Fence:
When we classify outliers we often talk about the inner and outer fences. The outer fence is represented by 


Mild (or possible) outliers and the Inner Fence:
The inner fence is represented by 


Therefore, extreme outliers have a constant of 3 times the IQR in the formula as opposed to the mild outlier’s constant of 1.5. Outliers in box plots are marked by using a star or asterisk (see the section on visual representations for an example).
Notes of Caution about Outliers
The first thing one should be careful to note. Outliers are still part of the data and hence are between the maximum and minimum values. It is not unusual for people to erroneously report that an outlier is "above the maximum". No data exists outside the maximum and minimum values. If outliers exist in your data set, then one of them is the maximum (or minimum). The inner fence does not describe the maximum and minimum values.
There are also many reasons why outliers appear (e.g. mistakes in data entry[2], natural variation, respondents giving untruthful answers to survey questions or errors in measurement etc). Often a researcher must make a decision of whether to include outliers in their final analysis. If the outliers are a mistake caused by an error in measurement, then a researcher might delete the outlier from the analysis. However, if there was no error then the researcher might keep the observation in the analysis as it contributes important information. Caution should always be used before deleting observations from a data set. Ensure you can justify why you did so. If you are unsure, consult an accredited statistician for advice.
The Variance and Standard Deviation
The standard deviation is another measure of spread or variability in a data set and is in some ways similar to the range just indicated. It is also much more favoured by statisticians than the range. One of the reasons the standard deviation is preferred by statisticians is because its calculation utilises every score in a set of measurements. The standard deviation is an exceptionally important measure of spread, so it is worthwhile spending a little time understanding the concept. It is helpful to think carefully about the term "standard deviation". The word deviation immediately indicates that this is a measure of variability or spread[3], in sharp contrast to any measure of central tendency. The adjective "standard" indicates that the quantity known as the standard deviation is calculated in a standard way; that is, one that is agreed upon by everyone. Before we examine how standard deviation is calculated, we need to first define what a deviation is.
Deviation from the Mean
In the previous section we looked at calculating the mean as a summary of a set of scores. In most cases, each score differs (at least slightly) from the mean; this difference is what we call the "deviation" or "displacement". It is important that we calculate each score’s deviation in the same way and so we define a score’s Deviation from the Mean as the result of subtracting the mean from that score, i.e.:

A positive deviation value indicates that the score is above the mean and a negative deviation value indicates that the score is below the mean. If we add up all the deviation values, we would get 0 (Can you think why?). This gives a way to double check that we have calculated all the deviation values correctly, but it also introduces a problem if we wanted to find an "average deviation" value.
Sum of Squares
To overcome the problem of having the sum of deviation values being equal to zero, we need to come up with a way to deal with the fact that some deviations are negative and some are positive. We could simply find the average of the magnitudes of the deviation values[4], but there is a better method. We square each of the deviation values to make them positive. In addition, this also results in extreme deviation values having a much greater magnitude when squared. If we add up these squared deviations we get what is called the Sum of Squares.
The Sum of Squares, typically denoted as 


Variance
Now that we have a way of finding a meaningful sum of (squared) deviations from the mean, we can use this to get an average deviation. This leads us to the following definition that the variance of a set of scores is the average of the squared deviation values for those scores.
If we simply divide 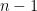
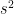

It is important to note that when we squared the deviation values, this also implies that we square the units. For example, if we were looking the hourly pay rate offered to university students by various fast food companies, then the squared deviation values would be measured in dollars squared (
Standard Deviation
The standard deviation gives the approximate average amount by which scores deviate or vary from the mean. In a more mathematical sense, the standard deviation is the square root of the variance. The formula for the standard deviation is as follows:

In a more simple sense, the standard deviation of a sample can be written as:

Probably one of the easiest and best ways to gain a good, basic notion of the standard deviation is first to consider how it is calculated. An example with a small data set is now presented. We will use the data set of time (in minutes) taken to walk to the cafe given in the examples above. Recall the times
The sample mean time was 
|
|
 |
 |
| 19 | 22.33 | -3.33 | 11.09 |
| 20 | 22.33 | -2.33 | 5.43 |
| 20 | 22.33 | -2.33 | 5.43 |
| 21 | 22.33 | -1.33 | 1.77 |
| 22 | 22.33 | -0.33 | 0.11 |
| 22 | 22.33 | -0.33 | 0.11 |
| 24 | 22.33 | 1.67 | 2.79 |
| 25 | 22.33 | 2.67 | 7.13 |
| 28 | 22.33 | 5.67 | 32.15 |
 |
66 |
As you can see in the table above all nine raw times have been listed in the left column. We denote the sample size or the number of observations in the data set as 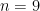


You will notice that 
The standard deviation just calculated reflects the average deviation from the sample mean. Therefore, the time taken to travel to university is expected to vary on average by 2.87 minutes from the mean,
Recall the data set of times taken to drive to university with the outlier of 127 mins included.
The mean of this data set was calculated to be 33.33 mins. Even though only one value has changed in this data set compared to the original, the unusual value of 127 has had the effect of dragging the mean towards a higher value. Now let’s figure out what happens to the standard deviation,
The table below shows how the sum of squares, 


|
|
|
|
| 19 | 33.33 | -14.33 | 205.44 |
| 20 | 33.33 | -13.33 | 177.78 |
| 20 | 33.33 | -13.33 | 177.78 |
| 21 | 33.33 | -12.33 | 152.11 |
| 22 | 33.33 | -11.33 | 128.44 |
| 22 | 33.33 | -11.33 | 128.44 |
| 24 | 33.33 | -9.33 | 87.11 |
| 25 | 33.33 | -8.33 | 69.44 |
| 127 | 33.33 | 93.67 | 8773.44 |
|
9900 |
The standard deviation is the most common measure of variability in a data set for interval and ratio data. It captures the variability, on average, of observations from the mean. Keep in mind that the standard deviation is not suitable for nominal and ordinal data.
Footnotes:
1. You may have learned about the "lower" (



2. On one occasion I was consulting for a PhD student who had a participant in their study that had their weight recorded as 697Kgs! Obviously a data entry error (should have been 69.7Kgs), but the effect on all of her analyses was profound. Once we corrected the error, suddenly the results of her analysis were much more reasonable.
3. Try not to confuse the word "deviation" with "deviant". Standard deviation is certainly not a measure of perversion.
4. You may (or may not) recall from calculus that the absolute value function is not differentiable at 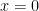
5. For those of you who really want to know the detailed reason, check out Wackerly (2002), page 438.
CITE THIS AS:
Ovens, Matthew. “Descriptive Statistics” Retrieved from YourStatsGuru.
First published 2010 | Last updated: 21 November 2024