

The first thing we should do with any data we obtain is to "draw a picture"! There are many great ways to present descriptive statistics in a visual way using graphical displays. Naturally this begs the question, what picture should you draw? Well that depends on what kind of data you have, i.e. nominal, ordinal, interval or ratio. While there are no hard and fast rules on what technique you must use for a given type of data, there are some that are obviously inappropriate. For example, you could hardly draw a boxplot for a nominal variable and you would be unlikely to draw a barchart for ungrouped ratio-level data. The graphical display of quantitative information is only limited by your imagination. You also have to be careful how you present your graph so as not to mislead your reader. The following, by no means comprehensive or exhaustive, will guide you through some of the typical data visualisation techniques used in statistics, starting with some of the more basic charts and ending with a demonstration of a more sophisticated technique using R.
Barcharts
Barcharts are a great way to graphically present a comparison between two or more groups on the counts in each group. For example, you might want to compare the number of siblings of a group of university students. Barcharts tend to be more suitable for summarising frequencies or percentages. As you can see in graph below, most students reported having only one sibling, with those have no siblings or two siblings the next most likely response. This simple barchart is a highly effective way of visualising the difference between the groups. Be careful though. Ensure you read the axis labels correctly so you do not misinterpret the chart. Also look out for barcharts not anchored at 0 on the vertical axis.

Note of caution:
Barcharts are often used incorrectly, sometimes for nefarious reasons. For example, an unscrupulous person might show you a barchart with the vertical axis not anchored at zero because it makes the difference between two groups (e.g. males/females) look bigger than it really is. Alternatively, a researcher, with the best of intentions, might incorrectly use a barchart to visually represent and compare the means of multiple groups, especially if it is common practice in their discipline. Readers should be aware that one cannot use a barchart to represent means or other single point estimates. The height of a vertical bar indicates that the group takes (or has progressed through) all values up to that height (e.g. our sibling data above). A single point estimate is precisely that, a single value, and therefore cannot take any other values, hence a barchart is not an appropriate representation.
Segmented Barcharts
Segmented barcharts are a variation on the concept of a barchart explained above. The segmented barchart is often used when there are two categorical variables we wish to compare. For example, suppose in our survey about siblings we also recorded the gender of the student answering. With this additional information we might like to see if male or female students tend to have more or less siblings. Adding the gender as an extra layer to our barchart, we can create the following segmented barchart.

From the above chart it doesn’t appear that we can see any substantial difference between the males and females in terms of the number of siblings. Of course, we could have used any number of other variables to split the data (e.g. pet ownership), provided we were careful to pick an appropriate categorical variable and it was relevant to our research question.
We could also present our data as a Percentage Segmented Barchart by adjusting the vertical axis to represent the percentage of the total in each category group. This method of presenting the data often helps in identifying if there are any potential differences between categories that might be worth investigating further. For our data, the percentage segmented barchart would look like this:

Piecharts
Another common method for presenting percentage related information is the pie chart. Whilst they are generally fairly easy for our readers to understand intuitively, it is all too easy for these charts to be misused, accidentally or by design. When looking at a pie chart, make sure that the slices/segments actually represent proportions of the whole (100%) and not proportions of something else. Occasionally, especially in marketing, you may see a pie chart where the slices add up to much more than 100% or where the slices are not proportional (e.g. the 33% slice is bigger than the 50% slice).
Piecharts are most appropriate for representing proportions in categorical data. For example, if we took our data about the number of siblings and drew a piechart of the proportion of students with 0, 1, 2, 3, 4, 5 or 6 siblings it would look something like this:

Of course, a good piechart should have a title and a legend if necessary to make things clearer for the reader!
Boxplots
One of the more useful charts to create for numerical data is the boxplot. The boxplot visually represents the quartiles of the data. These plots can help you quickly identify the shape of your distribution (i.e. how skewed or symmetric it is) and if there are any outliers present. We will come back to describing the shape of the data later, first let’s look at how the boxplot is constructed.
A boxplot can be drawn either vertically or horizontally, although it is more typical for stats packages to default to the vertical orientation, so we will describe the construction of a vertical chart. The chart starts with drawing the centre box which consists of three horizontal lines representing the first quartile (





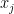

The plot below uses the "Chick Weight" data set available as part of R. The data consists of 50 newly hatched chickens, fed one of four diets, with their weight measured every two days and on the 21st day. Some of the chickens did not survive to 21 days. The plot shows the final recorded weights for all 50 chickens split by diet.

As you can see in the plot above, boxplots allow you to visually compare the distributions of data across groups. For example, we can see that Diet 3 had the highest median weight and Diet 1 had the lowest median weight. Diet 2 and Diet 4 had similar medians with Diet 4 being less variable than Diet 2. Diet 3 is negatively skewed
Histograms
Examples Created in R
The following are examples of more complex plots created using R.
Net Migration to Australia
This plot is created from a large dataset available on the Australian Bureau of Statistics (ABS) website. The code for generating this plot first downloads the data directly from the ABS and then processes it slightly. The researcher in this example was particularly interested in migrants born in the UK, New Zealand, India and China. The remaining data was grouped into "Southeast Asia & Oceania", "Rest of Asia", "Europe, North & South America, & Africa". Some migrants in the data set were identified as having been born in Australia or Norfolk Island (an Australian territory) and were therefore included as a separate group on the plot.

First published 2010 | Last updated: 21 November 2024