

One of the key techniques in a statistician’s toolbox is that of Null Hypothesis Significance Testing (NHST). Unfortunately, many textbooks, especially in the social sciences, either present only part of the true logic of the technique; oversimplify the logic leaving room for misconceptions to form; or, overcomplicate the logic by presenting each application (i.e. two-sample t-test vs paired t-test) as requiring a different procedure leading students to believe that NHST is difficult. Presented below are some of the more common misconceptions about NHST that, in this author’s opinion, the major ones that are oft repeated.
MISCONCEPTION – "When we make a decision in NHST, we have prooved which hypothesis is true"
After computing an appropriate decision statistic under NHST, one determines whether or not this provides sufficient evidence to reject the assumption that the Null Hypothesis is true. NHST is not a formal proof of any kind and at no stage prooves that any hypothesis is true. NHST only provides evidence to support the decision whether or not to reject the assumption that the Null Hypothesis is true.
MISCONCEPTION – "If we reject the Null Hypothesis then the Alternate Hypothesis must be true"
Similar to the previous point, if we conclude that there is sufficient evidence to reject the assumption that the Null Hypothesis is true, all we can say is that there was sufficient evidence to do so. We cannot conclude that the Alternate Hypothesis is true, only that the evidence suggests that the Null Hypothesis is not true. Since the Alternate Hypothesis should be a logical negation of the Null Hypothesis, it would then follow that the evidence also suggests that the Alternate Hypothesis may be a better explanation of the observed data. One needs to be very careful when reasoning with uncertainty as can be seen in the following example.
Suppose we have a certain statement or proposition, which we will call 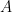



MISCONCEPTION – "We are 95% confident that the true parameter lies in this interval"
This is another tough one to break as so many textbooks and researchers write and/or teach this, I know that I am guilty of previously teaching this interpretation in my early teaching days. Plus, our human desire is to interpret any confidence interval this way, like it were some kind of probability statement. It is, however, very easy to show why this interpretation is incorrect. Suppose that we want to estimate, from our sample data, the value of the population mean and so we obtain a 95% confidence interval. Now if the true, but unknown, value of the population mean is 100 and we obtain an interval of (95,105) then our interval definitely captures the true value. If, however, our obtained interval is (85,95) then the true mean is definitely not in our interval. In either case, saying "We are 95% confident that the true mean is between 95 and 105" is akin to saying 
The correct interpretation of a confidence interval would be to state: "We obtain a 95% confidence interval of (95,105). Ninety-five percent of such intervals obtained in this manner would capture the true value of the population mean." – not a very satisfying interpretation, but a correct one. The confidence is in the method of obtaining the interval, not in an individual interval.
MISCONCEPTION – "A statistically significant result is important"
This is another popular misconception based on our natural human inclinations. The word significant, when used in statistics, simply means that there was sufficient evidence to reject the assumption that the Null Hypothesis is true, it does not say anything about the importance of the result. For example, one might develop a new pain relief tablet that relieves a patient’s pain ten seconds faster than the current best drug available. This difference might be statistically significant but is it really important? Typically we would argue that a result is important if it provides a practical or clinical difference, i.e. it is practically significant or clinically significant. Practical significance would be something like the new drug costing less, being easier to administer or easier to manufacture. Clinical significance would be something like the new drug having fewer side effects or better outcomes for the patient.
MISCONCEPTION – "We should only publish statistically significant results"
Sometimes referred to as the "publication bias" this misconception is actually contrary to good scientific practice. ALL results should be published, even those of experiments that didn’t work. To see why this is bad, suppose that only statistically significant results about a particular population are published. Now if want to attempt to answer the research question, "Is the population mean today greater than it was at this time last year?", we might go and get a random sample from the population, determine the sample mean and compute a decision statistic. If our decision statistic provides sufficient evidence to reject the assumption that the Null Hypothesis is true, we go off an publish our findings. Now if it is the case that the population mean hasn’t changed, then our findings, whilst statistically significant, are actually wrong and we have made what is called a Type I error. If, however, we don’t have sufficient evidence to reject the assumption that the Null Hypothesis is true, we keep the results to ourselves and don’t publish, even though our findings are correct. Now, if 100 identically and properly designed studies like ours are run, and all of these studies use an alpha level of 5% (see below), then we would expect 5 studies to be statistically significant purely by chance. As a result, if we only published statistically significant findings, the literature would suggest that the population mean has changed and most researchers wouldn’t be able to replicate the finding. If every study result is published, the literature would suggest that the five studies that had statistically significant results were the most likely the result of chance, not that the population mean had really changed.
MISCONCEPTION – "Confidence intervals are better than hypothesis tests"
The simple fact is that a confidence interval is just a different form of decision statistic you can use in a hypothesis test (see below). It is important to also note that a confidence interval is a property of the sample you have taken, in other words, it is a sample statistic just like the sample mean. What a confidence interval gives us is an interval estimate for the population parameter based upon the sample data. If the interval captures the null hypothesised value then the result is not statistically significant.
MISCONCEPTION – "Effect sizes are better than hypothesis tests"
An effect size is not better (or worse) than a hypothesis test, rather it tells you different information about the sample data and the obtained results, i.e. the magnitude of the observed phenomena. In general, one should always report an appropriate measure of effect size when reporting results. An effect size can be as simple as the difference between two sample means or more advanced like Omega-squared (
MISCONCEPTION – "Smaller p-values indicate a bigger effect"
A p-value does not measure anything about the effect or size of the difference observed. The p-value simply measures the probability of observing the sample data under the assumption that the Null Hypothesis is true. Many things can contribute to getting a small or large p-value, including sample size and/or measurement precision. The magnitude of the observed effect is measured by an appropriate Effect Size statistic — not the p-value.
MISCONCEPTION – "A p-value near the significance level can be interpretted as approaching a significant or non-significant result"
The p-value cannot be interpretted as approaching anything. The p-value is simply the probability of observing the sample data under the assumption that the Null Hypothesis is true. If the p-value is near the significance level then you may want to re-run your study with a different sample if you want to confirm whether or not the decision you made is repeated — this is what is meant by replication.
CITE THIS AS:
Ovens, Matthew. “Common Misconceptions about Hypothesis Testing”. Retrieved from YourStatsGuru.
First published 2018 | Last updated: 2 November 2024